For a long time, openness movements and initiatives with labels like “Open Access”, “Open Educational Resources” (OER) or “Linked Science” have been working on establishing a culture where scientific or educational resources are by default published with an open license on the web to be read, used, remixed and shared by anybody. With a growing supply of resources on the web, the challenge grows to learn about or find resources relevant for your teaching, studies, or research.
In this post, we describe the SkoHub project being carried out in 2019 by the hbz in cooperation with graphthinking GmbH. The project seeks to implement a prototype for a novel approach in syndicating content on the web by combining current web standards for sending notifications and subscribing to feeds with knowledge organization systems (KOS, sometimes also called “controlled vocabularies”).*
Current practices and problems
What are the present approaches to the problem of finding open content on the web, and what are their limitations?
Searching metadata harvested from silos
Current approaches for publishing and finding open content on the web are often focused on repositories as the place to publish content. Those repositories then provide (ideally standardized) interfaces for crawlers to collect and index the metadata in order to offer search solutions on top. An established approach for Open Access (OA) articles goes like this:
- Repositories with interfaces for metadata harvesting (OAI-PMH) are set up for scholars to upload their OA publications
- Metadata is crawled from those repositories, normalized and loaded into search indexes
- Search interfaces are offered to end users
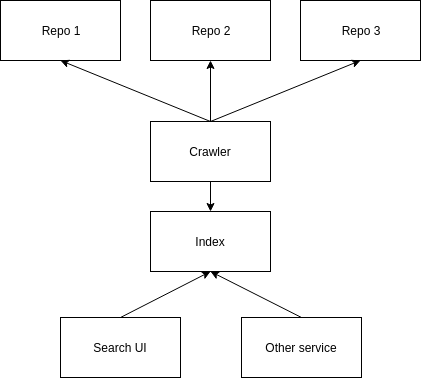
With this approach, subject-specific filtering is either already done when crawling the data to create a subject-specific index, or when searching the index.
Maintenance burden
When offering a search interface with this approach, you have to create and maintain a list of sources to harvest:
- watch out for new relevant sources to be added to your list,
- adjust your crawler to changes regarding the services’ harvesting interface,
- homogenize data from different sources to get a consistent search index.
Furthermore, end users have to know where to find your service to search for relevant content.
Off the web
Besides being error-prone and requiring resources for keeping up with changes in the repositories, this approach also does not take into account how web standards work. As Van de Sompel and Nelson 2015 (both co-editors of the OAI-PMH specification) phrase it:
“Conceptually, we have come to see [OAI-PMH] as repository-centric instead of resource-centric or web-centric. It has its starting point in the repository, which is considered to be the center of the universe. Interoperability is framed in terms of the repository, rather than in terms of the web and its primitives. This kind of repository, although it resides on the web, hinders seamless access to its content because it does not fully embrace the ways of the web.”
In short, the repository metaphor guiding this practice obscures what constitutes the web: resources that are identified by HTTP URIs (Uniform Resource Identifier).
Subject-specific subscription to web resources
So how could a web- or resource-centric approach to resource discovery by subject look like?
Of the web
To truly be part of the web, URIs are the most important part: Every resource (e.g. an OER) needs a URL that locates and identifies it. In order to make use of knowledge organization systems on the web, representing a controlled vocabulary using SKOS vocabulary is the best way to go forward: each subject in the vocabulary is identified by a URI. With these prerequisites, anybody can link their resources to subjects from a controlled vocabulary. This can be done e.g. by embedding LRMI, “Learning Resource Metadata Initiative” metadata as JSON-LD into the resource or its description page.
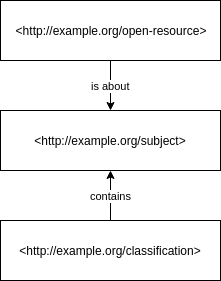
Web-based subscriptions and notifications
So, HTTP URIs for resources and subject are important to transparently publish and thereafter identify and link educational resources, controlled vocabularies and subject on the web. But with URIs as the basic requirement in place, we also get the possibility to utilize further web standards for the discovery of OER. For SkoHub, we make use of Social Web Protocols to build an infrastructure where services can send and subscribe to notifications for subject. The general setup looks as follows:
- Every element of a controlled vocabulary gets an inbox, identified by a URL.
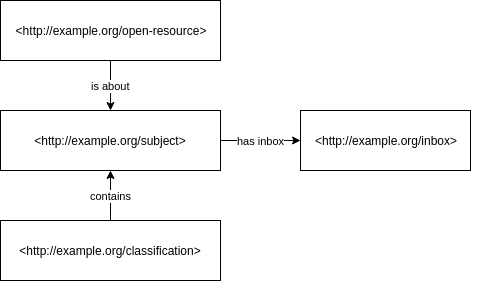
- Systems can send notifications to the inbox, for example “This is a new resource about this subject”.
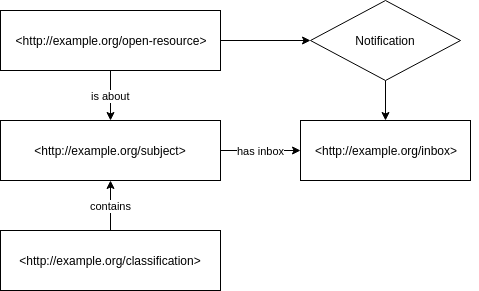
- Systems can subscribe to a subject’s inbox and will directly receive a notification as soon as it is received (push approach).
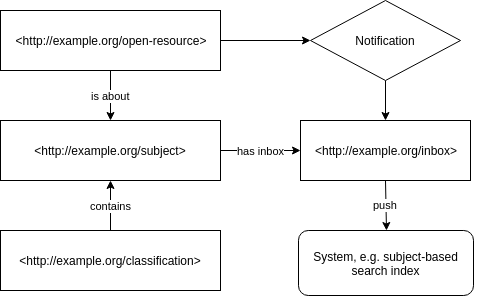
This infrastructure allows applications
- to send a notification to a subject’s inbox containing information about and a link to new content about this subject
- to subscribe to the inbox of a subject from a knowledge organization system in order to receive push updates about new content in real time.
Here is an example: a teacher is interested in new resources about environmental subjects. She subscribes to the subject via a controlled vocabulary like ISCED-2013 Fields of Education and Training. She then receives updates whenever a colleague publishes a resource that is linked to the subject.
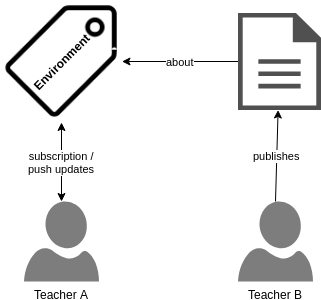
To be really useful, applications for subscribing to content should enable additional filters, to subscribe to combinations of subjects (e.g. “Environment” & “Building and civil engineering”) or to add addtional filters on educational level, license type etc.
Advantages
This subject-oriented notification/subscription approach to content syndication on the web has many advantages.
Push instead of pull
With the push approach, you subscribe once and content is coming from different and new sources without the subscriber having to maintain a list of sources. Of course quality control might become an issue. Thus, instead of whitelisting by administering a subscription list one would practice blacklisting by filtering out sources that distribute spam or provide low-quality content.
Supporting web-wide publications
Being of the web, SkoHub supports publications residing anywhere on the web. While the repository-centric approach favours content in a repository that provides interfaces for harvesting, with SkoHub any web resource can make use of the notification mechanism. Thus, content producers can choose which tool or platform best fits their publishing needs, be it YouTube, a repository, hackmd.io or else. The only requirement is for publications to have a stable URL and, voilà, they can syndicate their content via KOS.
Knowledge organization systems are used to their full potential
This additional layer to the use of Knowledge Organization Systems makes them much more powerful (“KOS on steroids”) and attractive for potential users.
Encouraging creation and use of shared Knowledge Organization Systems across applications
In the German OER context it is a recurring theme that people are wishing everybody would use the same controlled vocabularies so that data exchange and aggregation required less mapping. With a SkoHub infrastructure in place, there are big additional incentives on going forward in this direction.
Incentive for content producers to add machine-readable descriptions
When subject indexing becomes tantamount with notifying interested parties about one’s resources, this means a huge incentive for content producers to describe their resources with structured data doing subject indexing.
SkoHub project scope
The SkoHub project has four deliverables. While working on the backend infrastructure for receiving and pushing notifications (skohub-pubsub), we also want to provide people with means to publish a controlled vocabulary along with inboxes (skohub-ssg), to link to subjects and send notifications (skohub-editor) and to subscribe to notifications in the browser (skohub-deck).
skohub-pubsub: Inboxes and subscriptions
Code: https://github.com/hbz/skohub-pubsub
This part provides the SkoHub core infrastructure, setting up basic inboxes for subjects plus the ability of subscribing to push subscriptions for each new notification.
skohub-ssg: Static site generator for Simple Knowledge Organization Systems
Code: https://github.com/hbz/skohub-ssg
This part of the project covers the need to easily publish a controlled vocabulary as a SKOS file, with a basic lookup API and a nice HTML view including links to an inbox for each subject.
skohub-editor: Describing & linking learning resources, sending notifications
Code: https://github.com/hbz/skohub-editor
The editor will run in the browser and enable structured description of educational resources published anywhere on the web. It includes validation of the entered content for each field and lookup of controlled values via the API provided by skohub-ssg.
skohub-deck: Browser-based subscription to subjects
Code: https://github.com/hbz/skohub-deck
The SkoHub deck is a proof of concept to show that the technologies developed actually work. It enables people to subscribe to notifications for specific subjects in the browser. The incoming notifications will be shown in a Tweetdeck-like interface.
Outlook
The project will be completed by end of 2019. We intend to provide updates about the process during the way. Next up, we will explain the technical architecture in more detail, expanding on our use of social web protocols. Furthermore, we will provide updates on the development status of the project.
* Note that while SkoHub has clear similarities with the “Information-Sharing Pipeline” envisioned in Ilik and Koster 2019 regarding the use of social web protocols on authority data, there is also a fundamental difference: While Ilik and Koster are talking about sharing updates of authority entries themselves (e.g. receiving updates for a person profile to be considered for inclusion in one’s own authority file), SkoHub is about sharing new links to an entry in an authority file or other controlled vocabulary.
References
de Sompel, Herbert Van / Nelson, Michael L. (2015): Reminiscing About 15 Years of Interoperability Efforts. D-Lib Magazine 21 , no. 11/12. DOI: 10.1045/november2015-vandesompel
Ilik, Violeta / Koster, Lukas (2019): Information-Sharing Pipeline, The Serials Librarian, DOI: 10.1080/0361526X.2019.1583045. Preprint: https://doi.org/10.31219/osf.io/hbwf8
Comments? Feedback? Just add an annotation with hypothes.is.