We have recently improved our GND reconciliation service for OpenRefine based on two real-world examples sent to us by users.* In this post we want to share these examples, focusing on using additional properties to improve matching. We will be reconciling persons using birth and death dates as well as occupations and affiliations. For a simple example and general introduction check out our documentation on GND reconciliation for OpenRefine.
Birth and death dates
The first data set is a list of person names along with their birth and death dates. We want to match these names to GND entities, using the life dates to improve matches. To get started, import persons.csv into your OpenRefine instance:
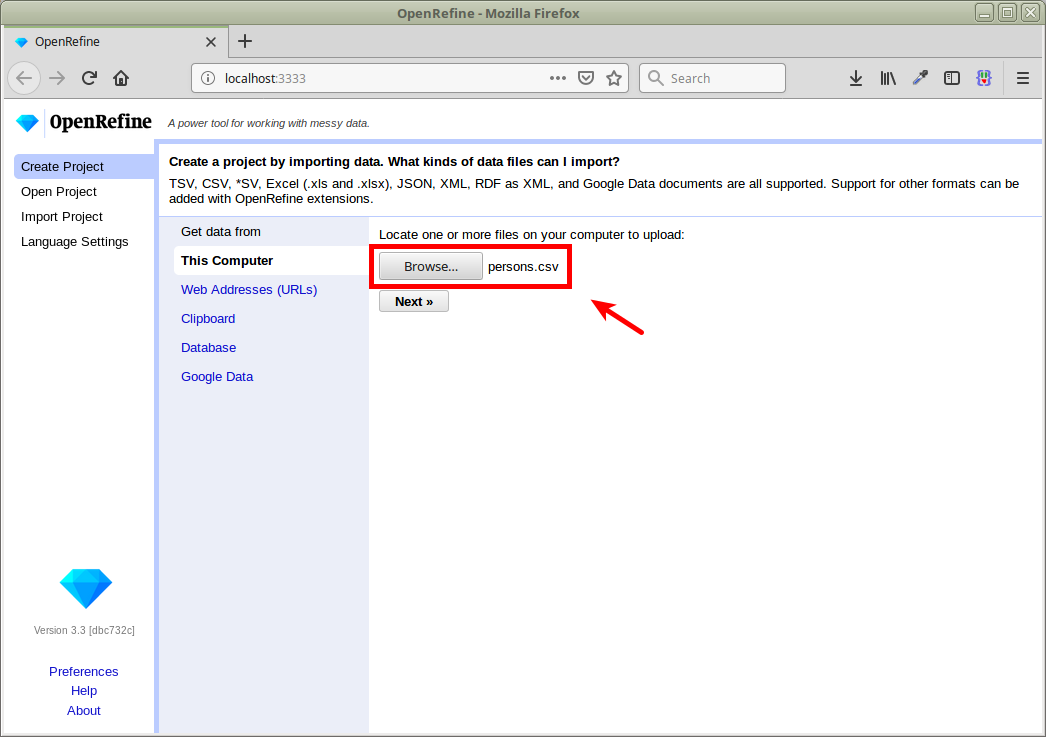
The preview should look like this:
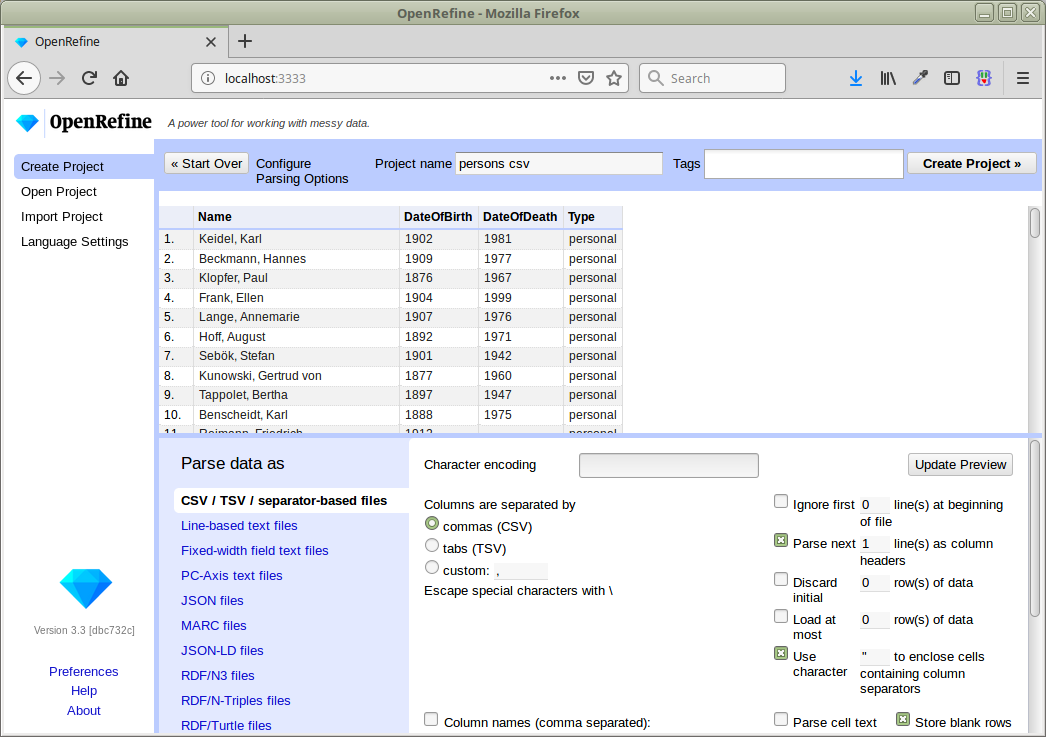
We can then create the project:
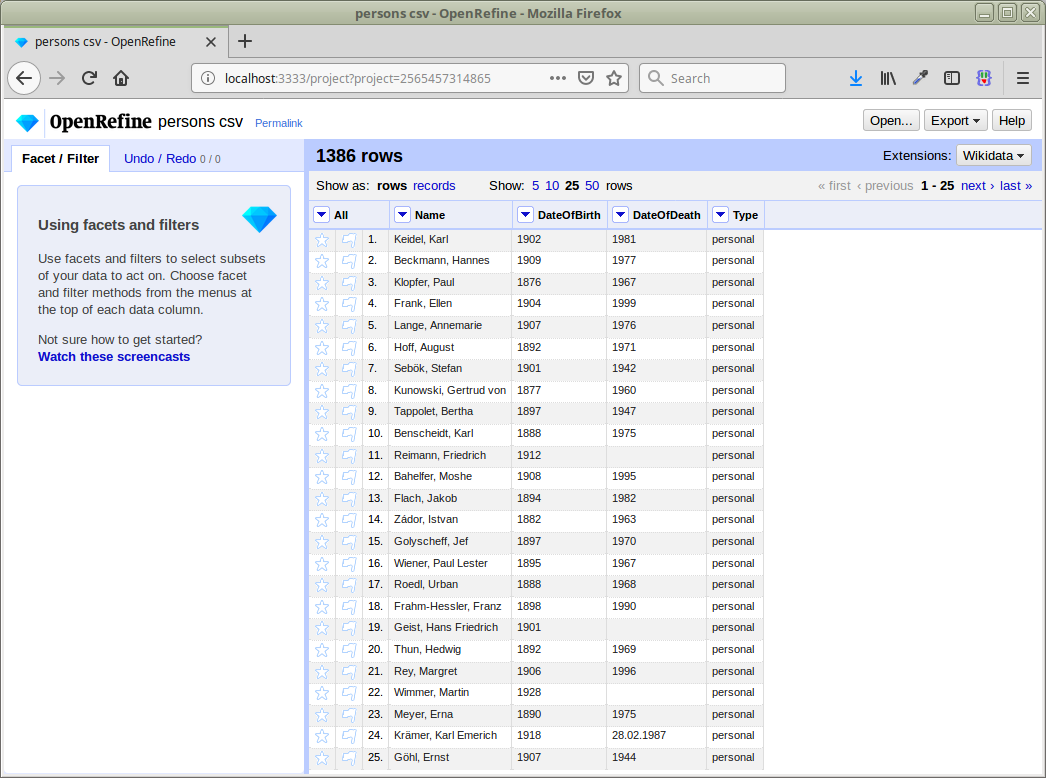
To get a feeling for the matching quality, let’s just reconcile the names against type DifferentiatedPerson using our service at https://lobid.org/gnd/reconcile:
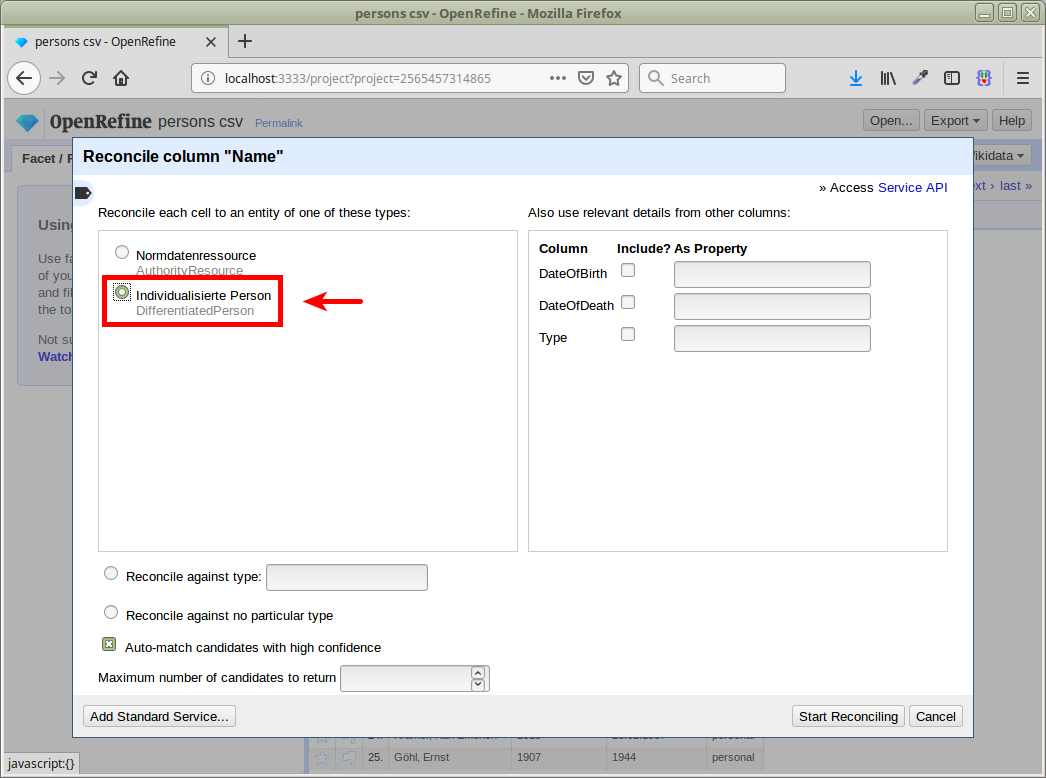
If we look at the resulting facet, we see that we got matches for about two thirds of our entries (911 matched, 475 unmatched):
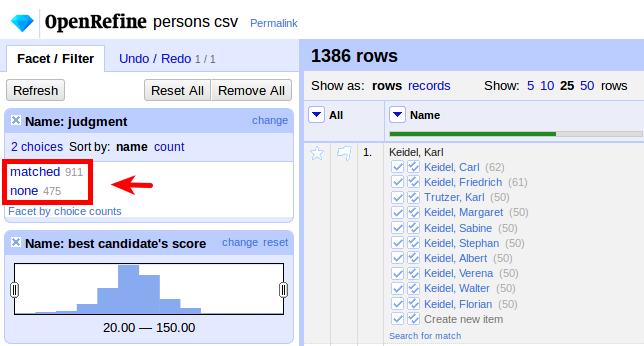
To improve the matches using the life dates, first let’s check how dates are represented in the GND. If we take a look at the data for Ellen Frank, we see that the dates are stored in ISO 8601 format:
"dateOfDeath": [
"1999-09-17"
],
"dateOfBirth": [
"1904-03-09"
]
Since the dates in our table are just years, we want to transform the values:
In particular, we want to add an * to use our years as a prefix when matching, so we use value + "*" as our transformation expression:
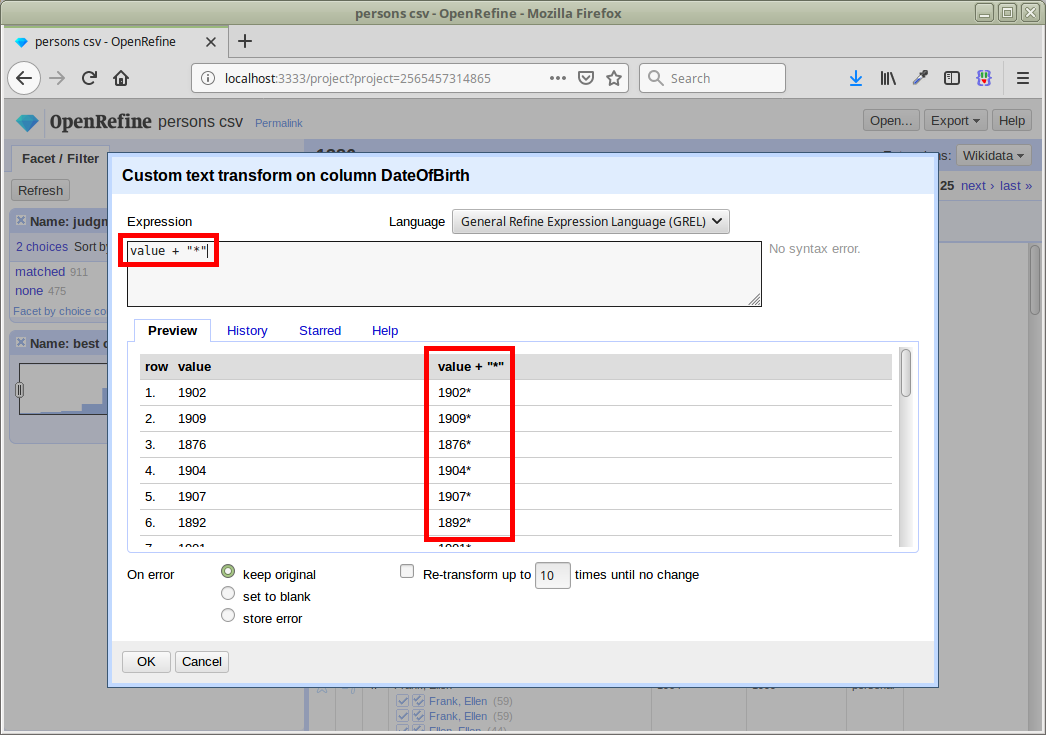
We perform these steps for both the DateOfBirth and DateOfDeath columns.
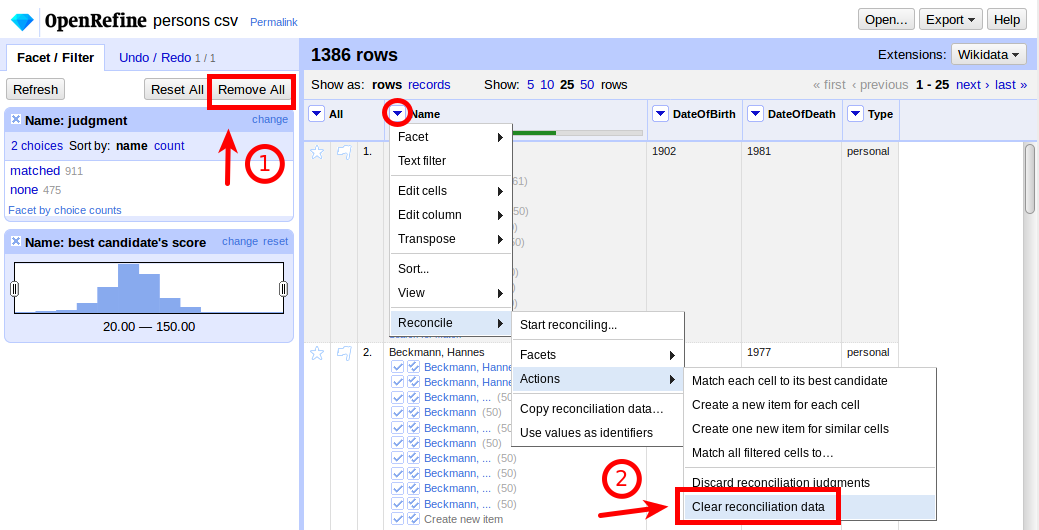
Before we reconcile again, passing the modified dates as additional properties, we Remove All facets and Clear reconciliation data:
Now we reconcile again, passing the life dates as additional properties. Properties are suggested while typing into the text input box:
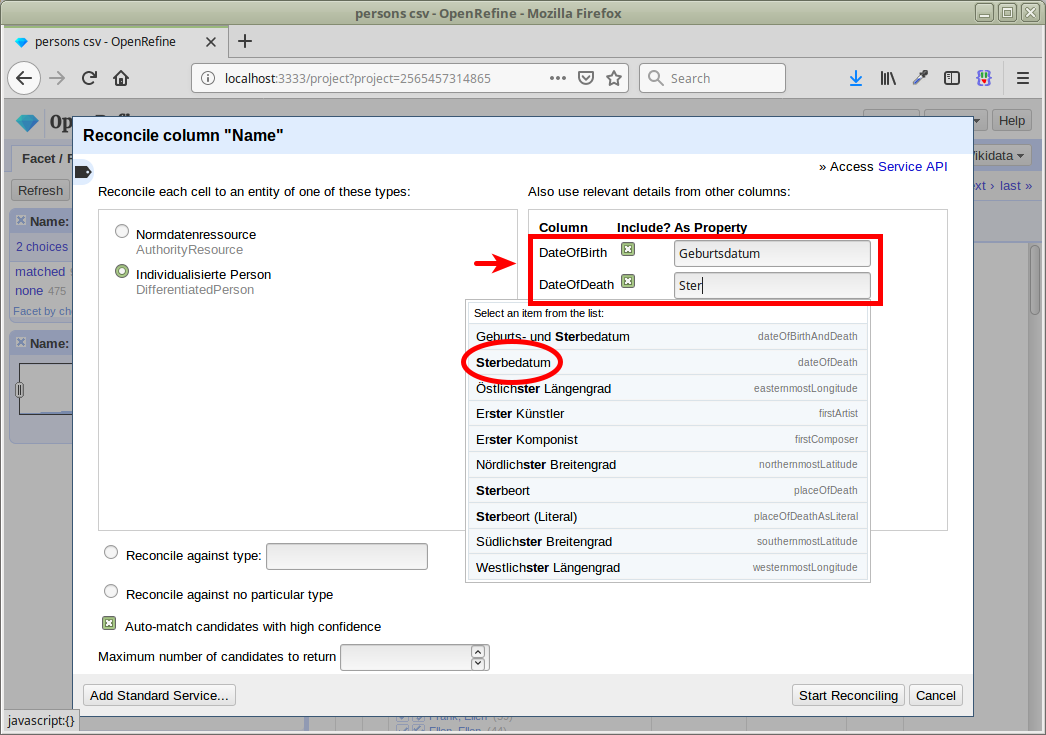
We check the results again, and see that we now have more than 90% matched (1277 matched, 109 unmatched):
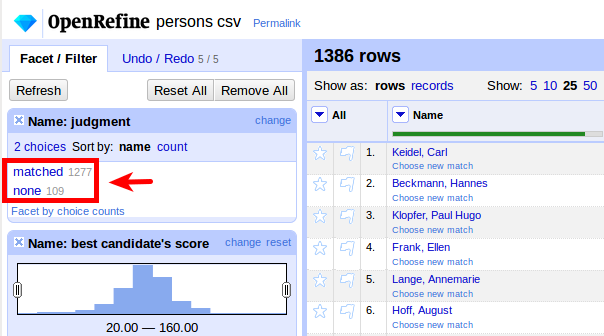
The remaining entries can be matched manually using previews and entry suggestions, see our general documentation for details. You can download the complete workflow to run it (Undo / Redo tab, Apply...) on the input data in a new project.
Occupations and affiliations
The second data set is a list of politician names and their associated parties. We want to match these names to GND entities, using the parties to improve matches. To get started, import politicians.csv into your OpenRefine instance:
The preview should look like this:
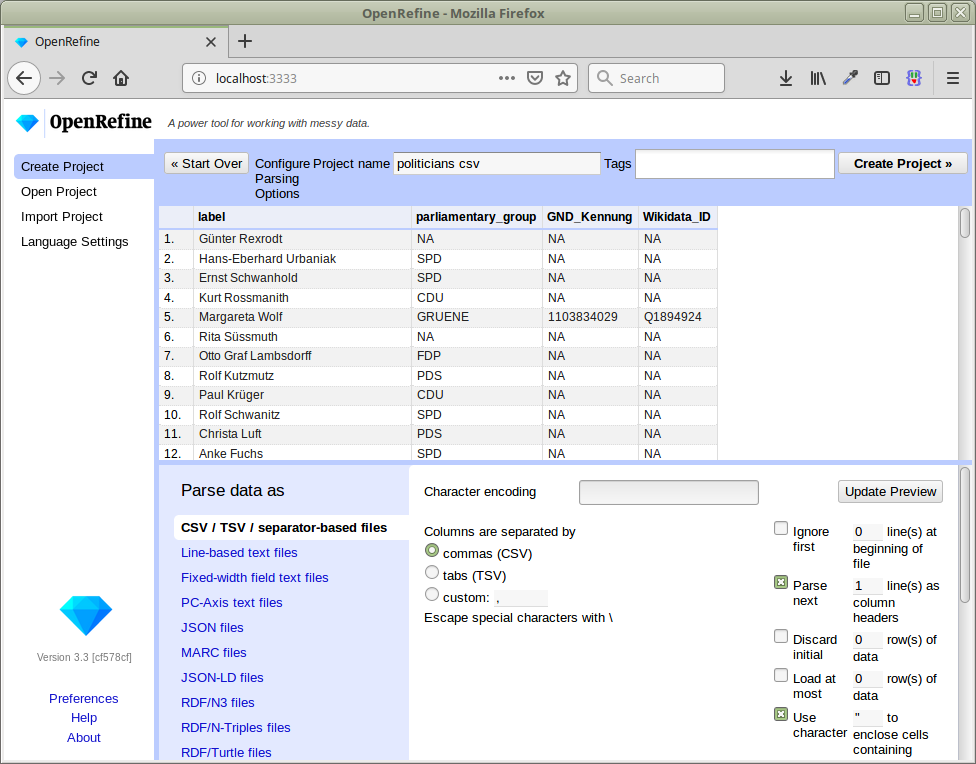
We can then create the project:
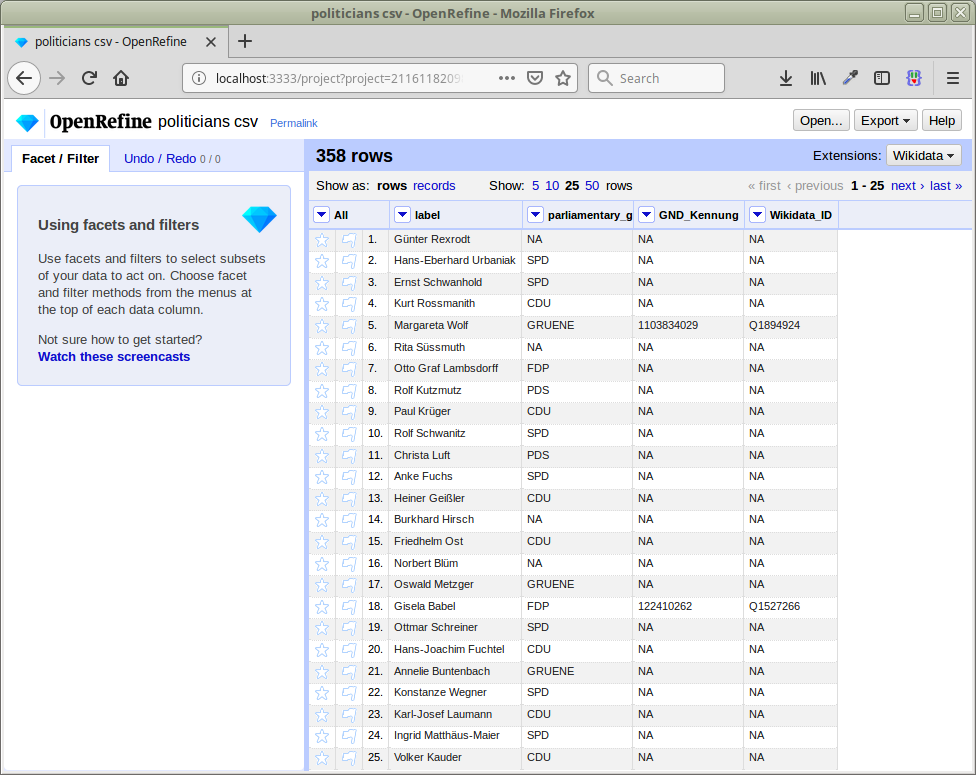
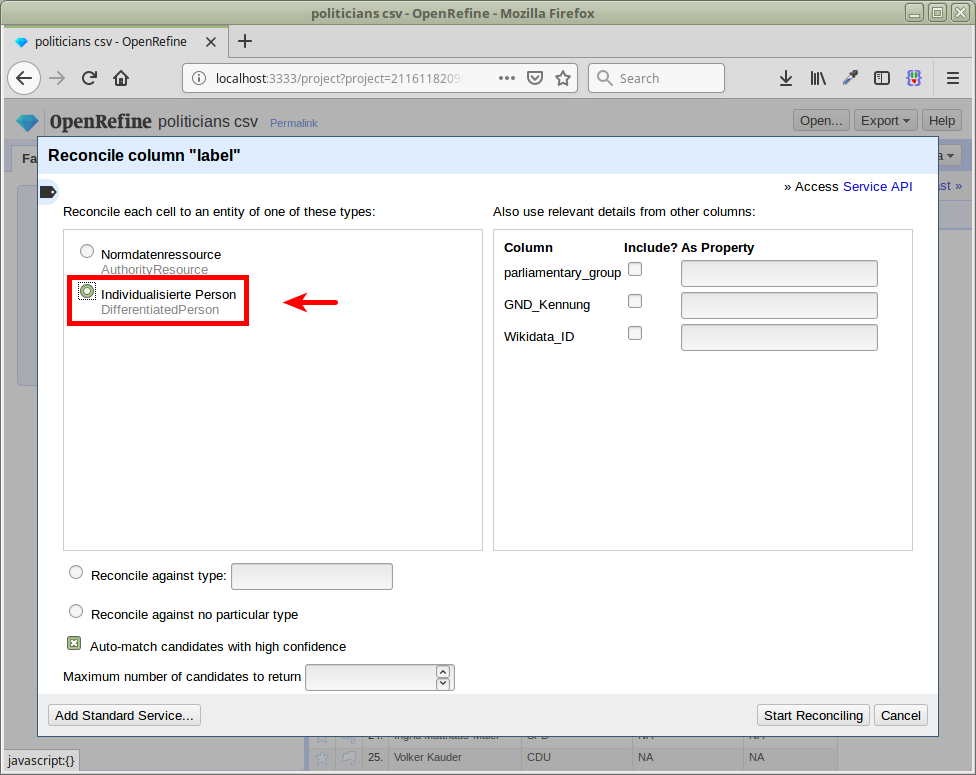
Again, to get a feeling for the matching quality, let’s just reconcile the names against type DifferentiatedPerson using our service at https://lobid.org/gnd/reconcile:
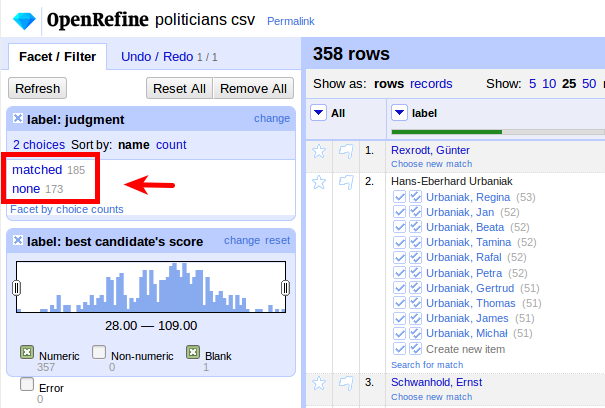
If we look at the resulting facet, we see that we got matches for a little more than half of our entries (185 matched, 173 unmatched):
To improve that using the parties, first let’s check how political parties are represented in the GND. If we take a look at the data for Willy Brandt, we see that his party is stored in the affiliation field:
"affiliation": [
{
"id": "https://d-nb.info/gnd/2022139-3",
"label": "Sozialdemokratische Partei Deutschlands"
}
]
Since the label does not contain the abbreviated form used in our data (SPD), we should match based on the ID. To do so, we want to transform the abbreviations to their GND IDs:
- SPD →
https://d-nb.info/gnd/2022139-3 - CDU →
https://d-nb.info/gnd/7230-8 - GRUENE →
https://d-nb.info/gnd/2124337-2 - FDP →
https://d-nb.info/gnd/37037-X - LINKE →
https://d-nb.info/gnd/10173685-X - PDS →
https://d-nb.info/gnd/5010217-5
We can do this by opening a text facet for the abbreviations: Facet > Text facet:
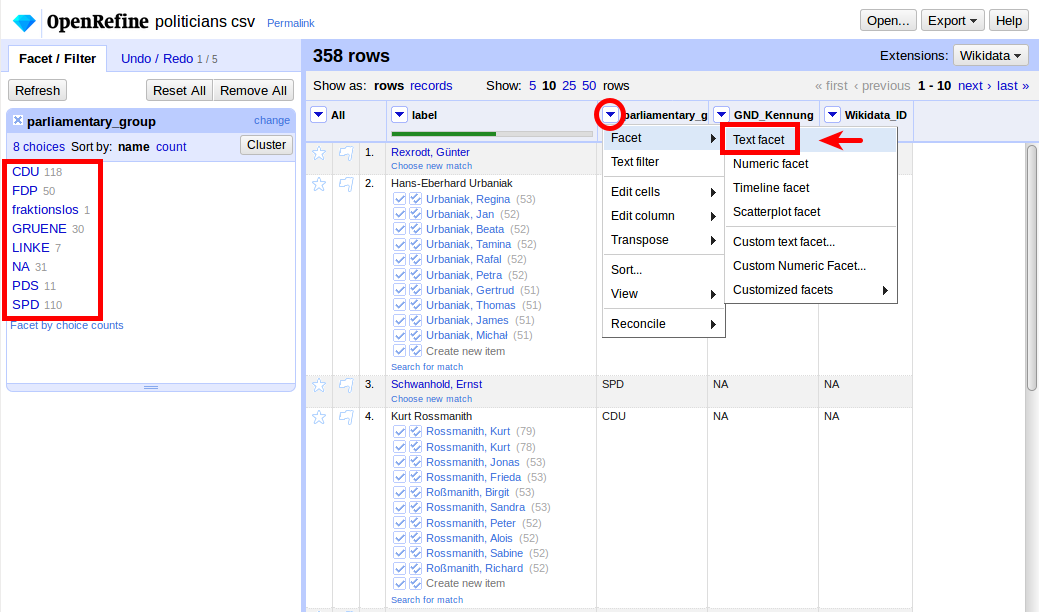
If you hover over one of the entries, you get an “edit” link:
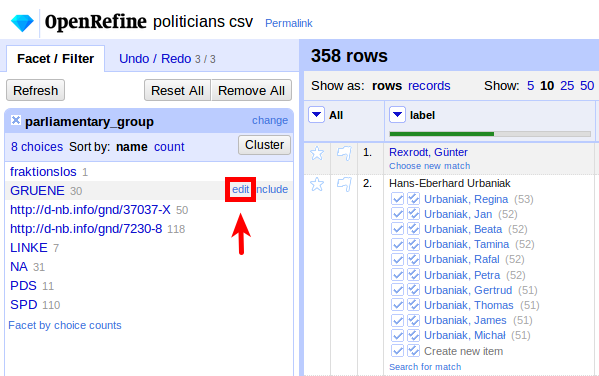
You can perform all these transformations at once. In the Undo / Redo tab, click Apply...:
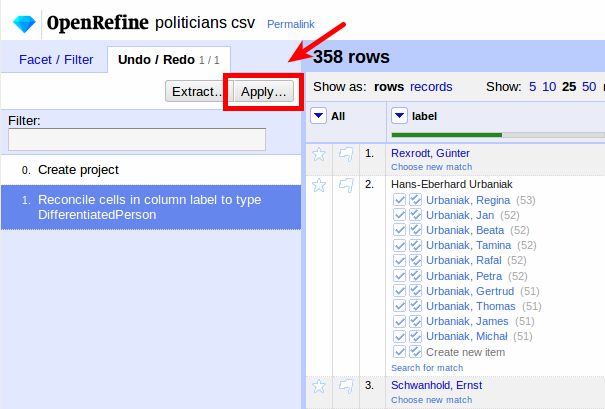
Paste the following JSON (we first duplicate the original column to retain the original values):
[
{
"op": "core/column-addition",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"baseColumnName": "parliamentary_group",
"expression": "grel:value",
"onError": "set-to-blank",
"newColumnName": "affiliation",
"columnInsertIndex": 2,
"description": "Create column affiliation at index 2 based on column parliamentary_group using expression grel:value"
},
{
"op": "core/mass-edit",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "affiliation",
"expression": "value",
"edits": [
{
"from": [
"GRUENE"
],
"fromBlank": false,
"fromError": false,
"to": "https://d-nb.info/gnd/2124337-2"
},
{
"from": [
"NA"
],
"fromBlank": false,
"fromError": false,
"to": ""
},
{
"from": [
"FDP"
],
"fromBlank": false,
"fromError": false,
"to": "https://d-nb.info/gnd/37037-X"
},
{
"from": [
"CDU"
],
"fromBlank": false,
"fromError": false,
"to": "https://d-nb.info/gnd/7230-8"
},
{
"from": [
"SPD"
],
"fromBlank": false,
"fromError": false,
"to": "https://d-nb.info/gnd/2022139-3"
},
{
"from": [
"LINKE"
],
"fromBlank": false,
"fromError": false,
"to": "https://d-nb.info/gnd/10173685-X"
},
{
"from": [
"PDS"
],
"fromBlank": false,
"fromError": false,
"to": "https://d-nb.info/gnd/5010217-5"
}
],
"description": "Mass edit cells in column affiliation"
}
]
Then click Perform Operations:
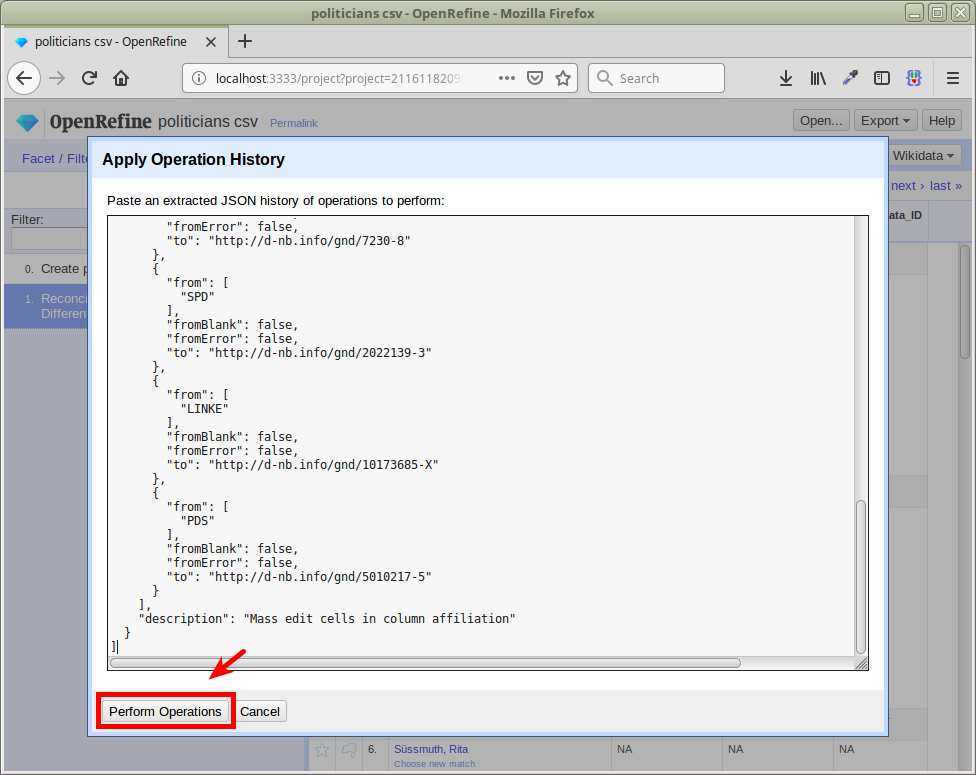
Again, before we reconcile with the additional affiliation IDs, we Remove All facets and Clear reconciliation data:
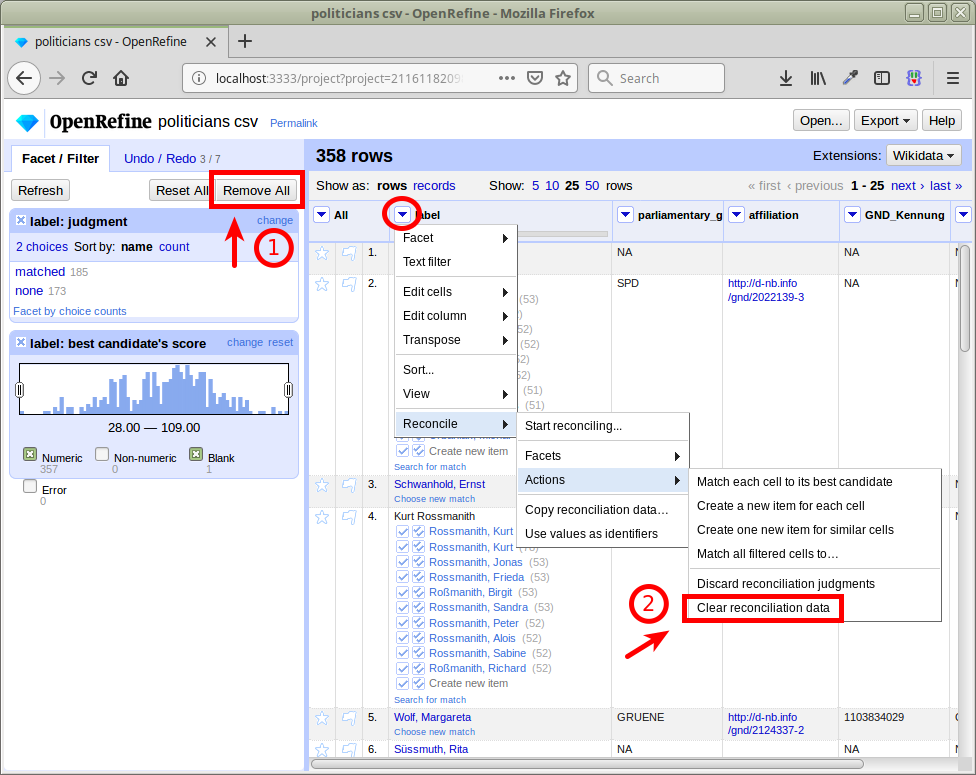
Now we reconcile again, passing the affiliation IDs as an additional property:
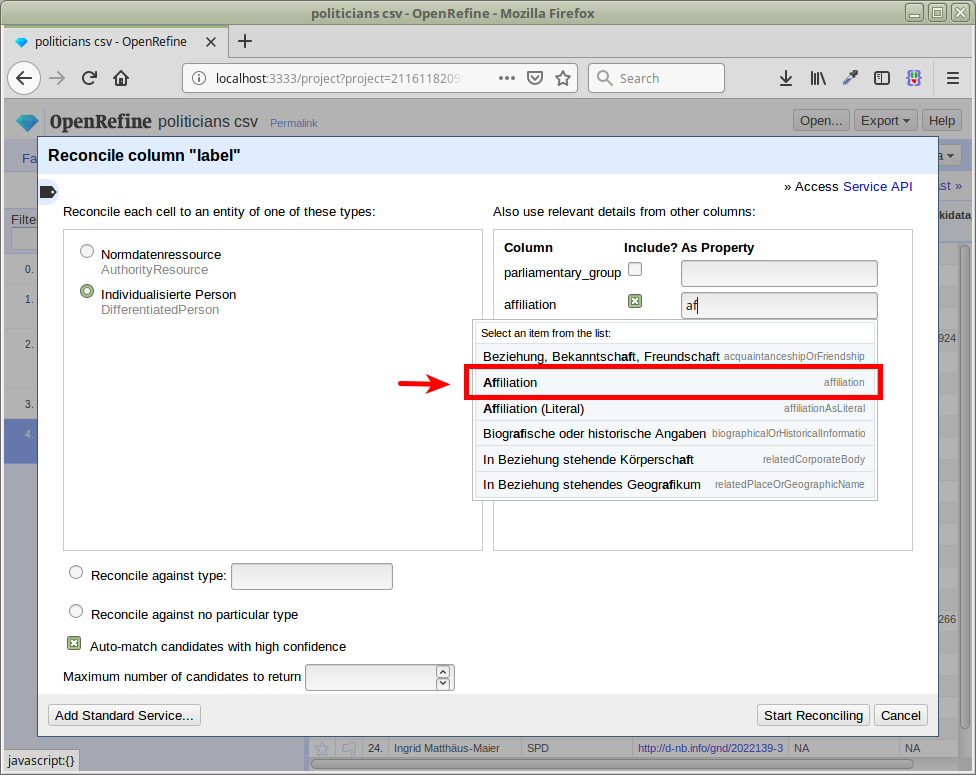
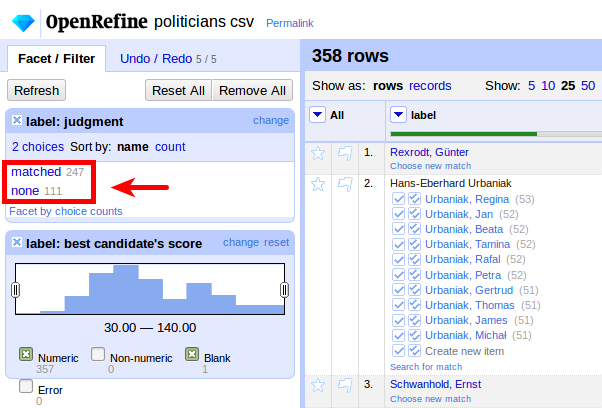
With this, we now get 247 matches:
To further improve reconciliation results, let’s use the fact that we know the profession of the people we’re trying to match: they are all politicians. To do so, we’ll add a column (label column > Edit column > Add column based on this column...), and use "Politik*" as the expression:
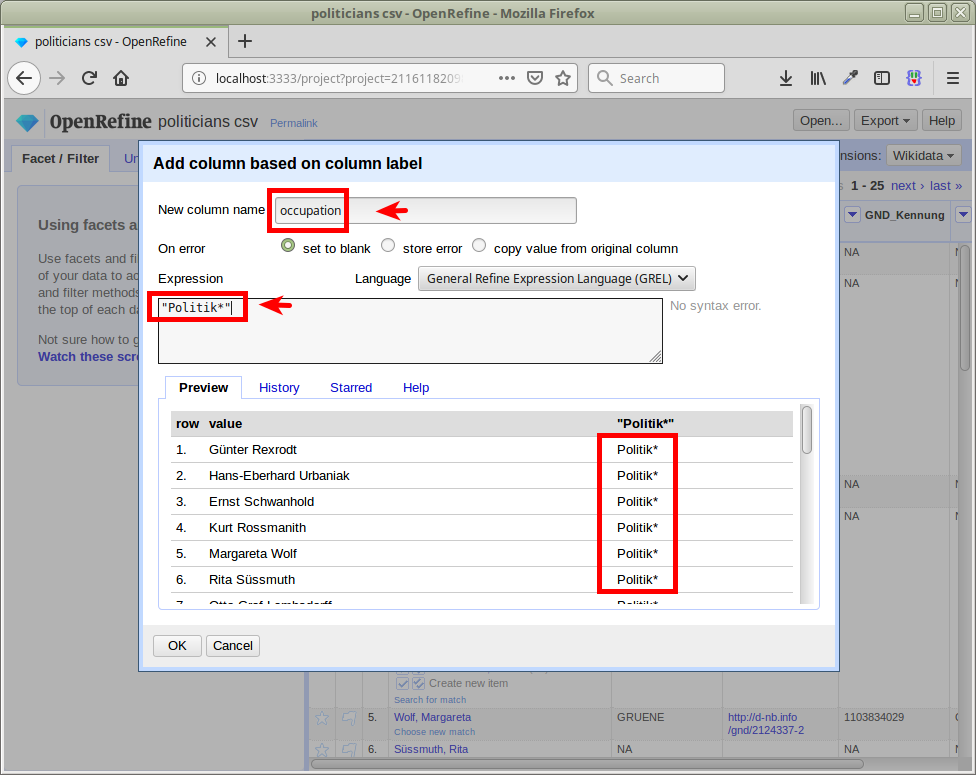
Using Politik* results in matching both male (Politiker) and female (Politikerin) forms, as well as related occupations like Politikwissenschaftler and Politikwissenschaftlerin.
We now Remove All facets and Clear reconciliation data as before, and reconcile again, this time passing both the occupation and affiliationcolumns as additional properties:
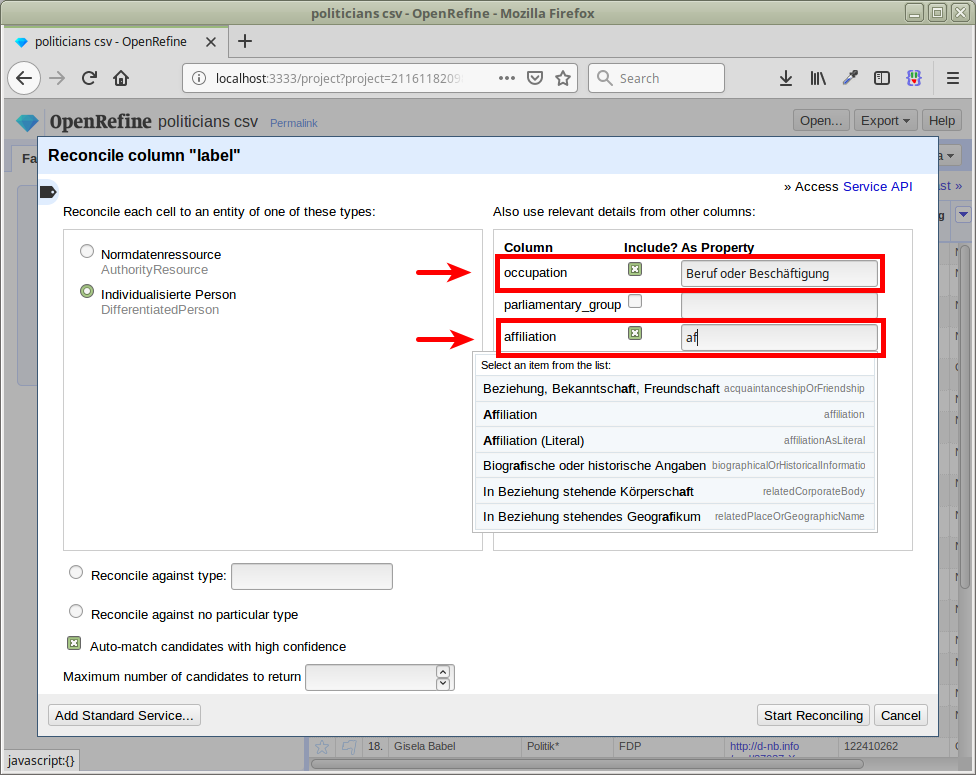
Checking our final result, we now have more than 75% matched entries (275 matched, 83 unmatched):
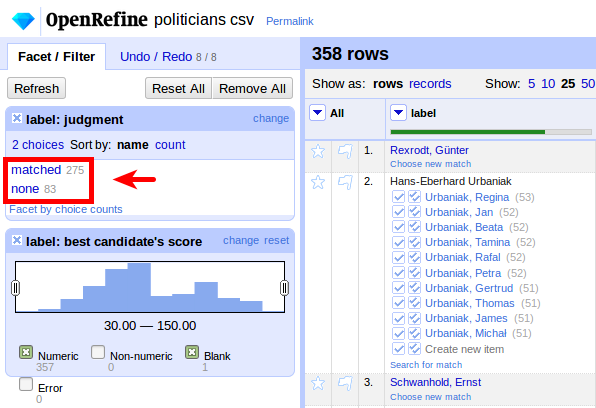
Again, the remaining entries can be matched manually using previews and entry suggestions, see our general documentation for details. You can download the complete workflow to run it (Undo / Redo tab, Apply...) on the input data in a new project.
*Thanks to Felix Ostrowski and Florian Gilberg for providing these data sets.
Comments? Feedback? Just add an annotation with hypothes.is.