At last year’s SWIB conference (SWIB18) the lobid team offered a workshop “From LOD to LOUD: making data usable”. In the workshop, participants carried out the steps to create well-structured JSON-LD from RDF data, index it in Elasticsearch, build a simple web application for querying it and use the data with tools like OpenRefine and Kibana. For details, see the slides at https://hbz.github.io/swib18-workshop/.
We had to decide which RDF dataset we would use to be treated in the workshop. In the end, we chose the Bibframe works dataset (but not the instances dataset) that the Library of Congress (LoC) had published in June. As preparation for the workshop, we did an experimental not very quick but rather dirty conversion of the N-Triples to JSON-LD and indexed the whole Bibframe dataset into Elasticsearch.
The JSON-LD context
The context plays an essential role when creating JSON-LD and in increasing its usability. A central function of the context is to map long property URIs to short keys to be used in the JSON. For example with the line "label": "http://www.w3.org/2000/01/rdf-schema#label" in the context, I can now use the key "label" in a JSON-LD document and when including the context in the document (for example by referencing it like "@context": "https://example.org/context.jsonld") the key-value pair can be translated to an RDF triple. The context is also used to declare that the values of a specific key should be interpreted as URIs (by saying "@type": "@id") or as a date (example) or to enforce that a key always is used with an array ("@container": "@set"), see e.g here.
Unfortunately, nobody had already created a context we could reuse. And as a lot of properties and classes are used in the Bibframe works dataset the context grew quite big and its creation took a lot of time and iterations. The result can be found here. It is not perfect but may be of help to others who want to do something similar with the Bibframe dataset.
So we used this JSON-LD context to create JSON-LD from the Bibframe N-Triples and indexed the result in Elastisearch. For some more information on how to create JSON-LD from N-Triples see Fabian’s blog post about the first part of the workshop.
Querying the index & visualizing with Kibana
The index can be found here: http://es.labs.lobid.org/loc_works/_search. You get direct access to the index without a UI. You can use the Kibana instance running against that index as UI. Check it out at http://kibana.labs.lobid.org/. There you can for example access the index pattern which gives you an overview over all the fields you can query.
For querying the data, you can use the Elasticsearch Query String Syntax which allows composing easy but also rather complex queries against the data. For setting up a Kibana visualization see the Kibana documentation or take a look at the example visualizations.
Here are some examples which you can use to build your own queries and visualizations:
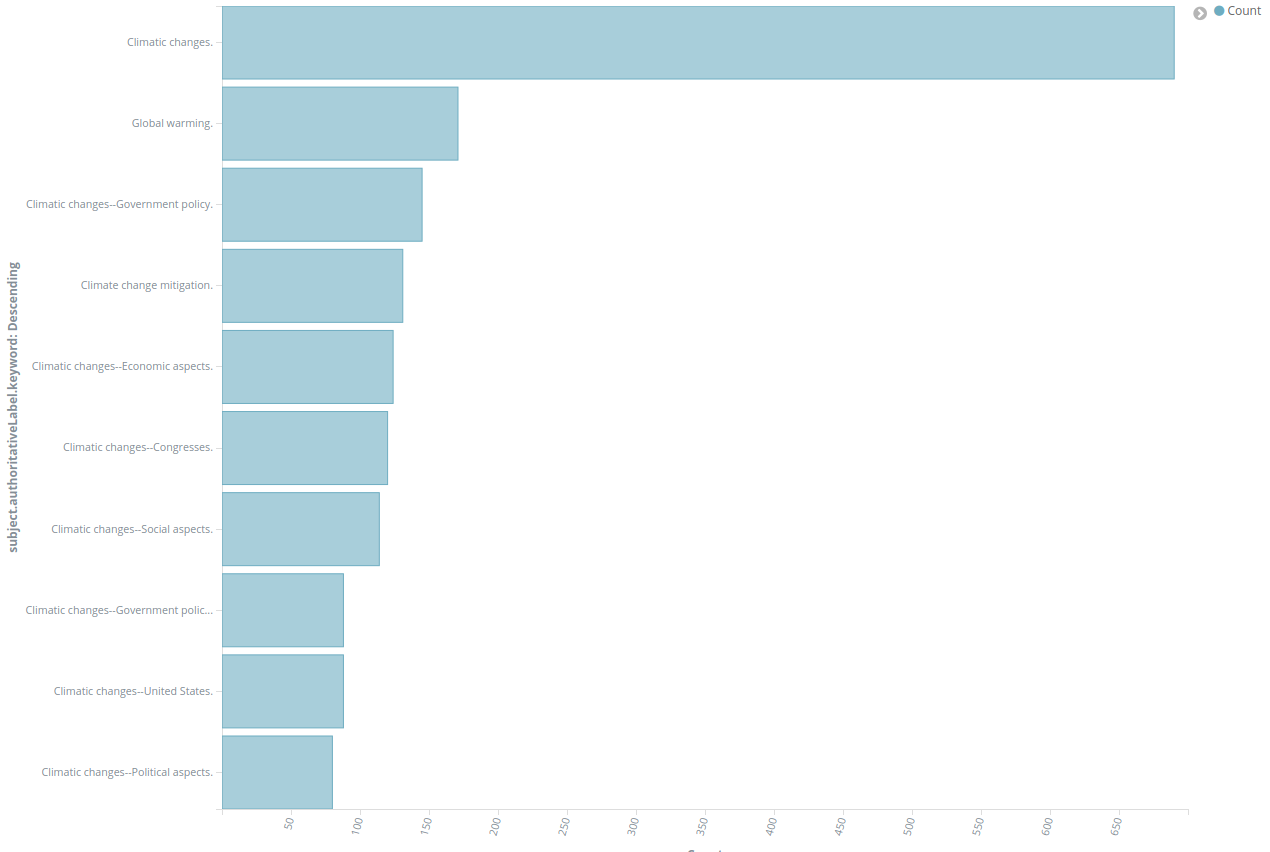
Querying for “climate change”:
All records containing the phrase “climate change” somewhere, listing the first 100 (using the size parameter) of a total 5124: http://es.labs.lobid.org/loc_works/_search?q=%22climate%20change%22&size=100
If you want to know which subject headings are used in those records, look at the Kibana visualization showing the top 10 subject headings:
Query specific fields:
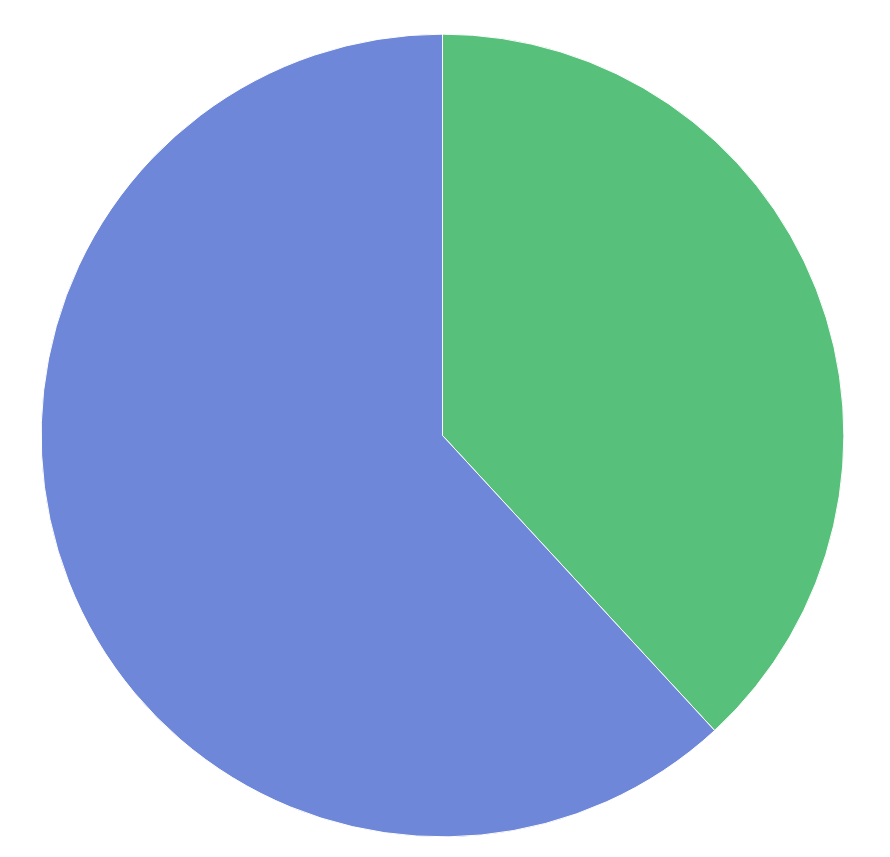
Records with topic “Cat owners”: http://es.labs.lobid.org/loc_works/_search?q=subject.label:%22cat%20owners%22
And here a visualization comparing the number of record about “Cat owners” (green) with those about “Dog owners” (blue):
Boolean operators:
You can use boolean operators connecting two fields, e.g. querying for works about “Dog owners” (subject.label) in German (language.id): subject.label:”dog owners”+AND+language.id:”http://id.loc.gov/vocabulary/languages/ger” (Fun fact: There are no titles about cat owners in German.)
You can also use boolean operators on the content of one field by using brackets, e.g. subject.authoritativeLabel:(cat*+AND+psychology) (query)
Range queries:
All resources modified in 2017: adminMetadata.changeDate:[2017-01-01+TO+2017-12-31]
All resources created in 2017: adminMetadata.creationDate:[2017-01-01+TO+2017-12-31]
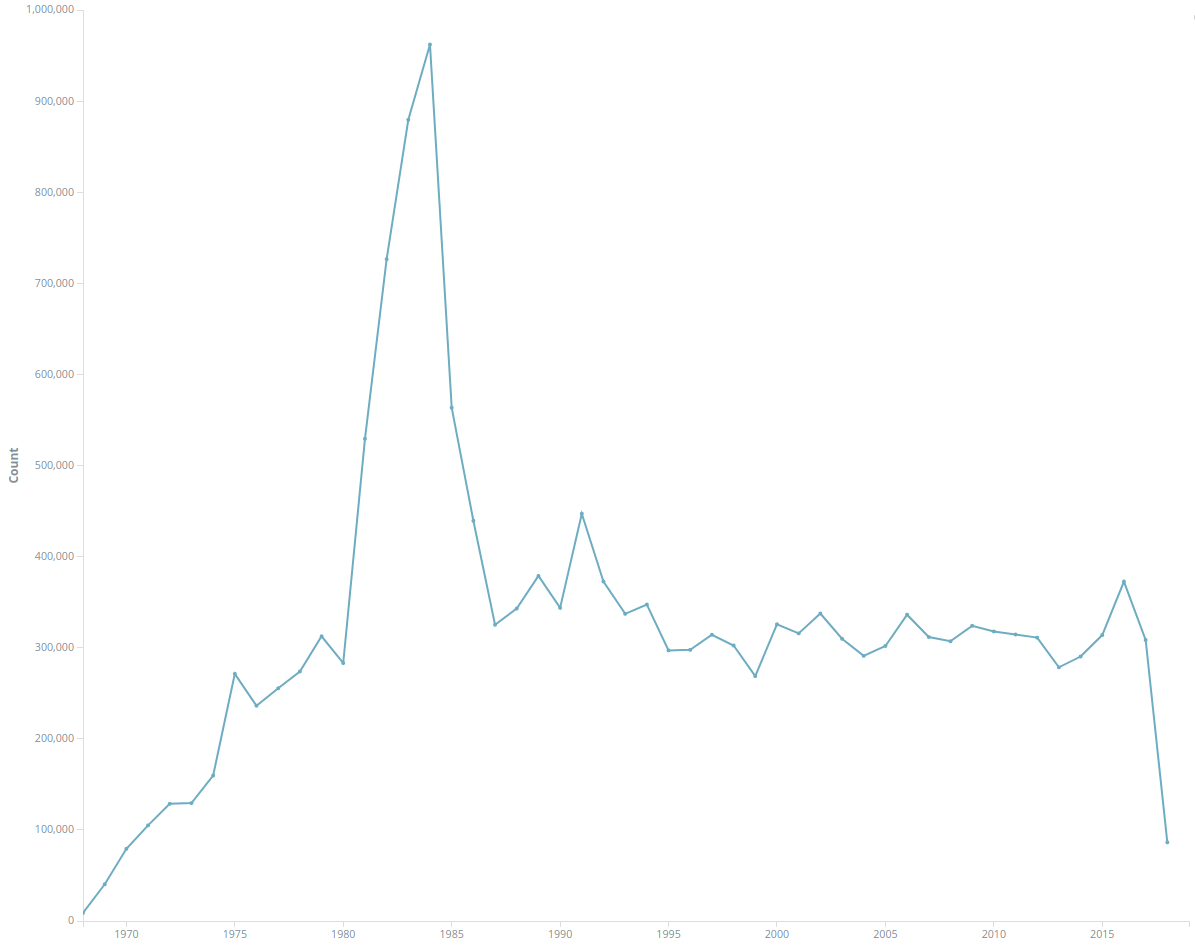
You can also use date fields for visualizations, e.g. record creation date by year (What happened from 1981 to 1985?):
_exists_ queries:
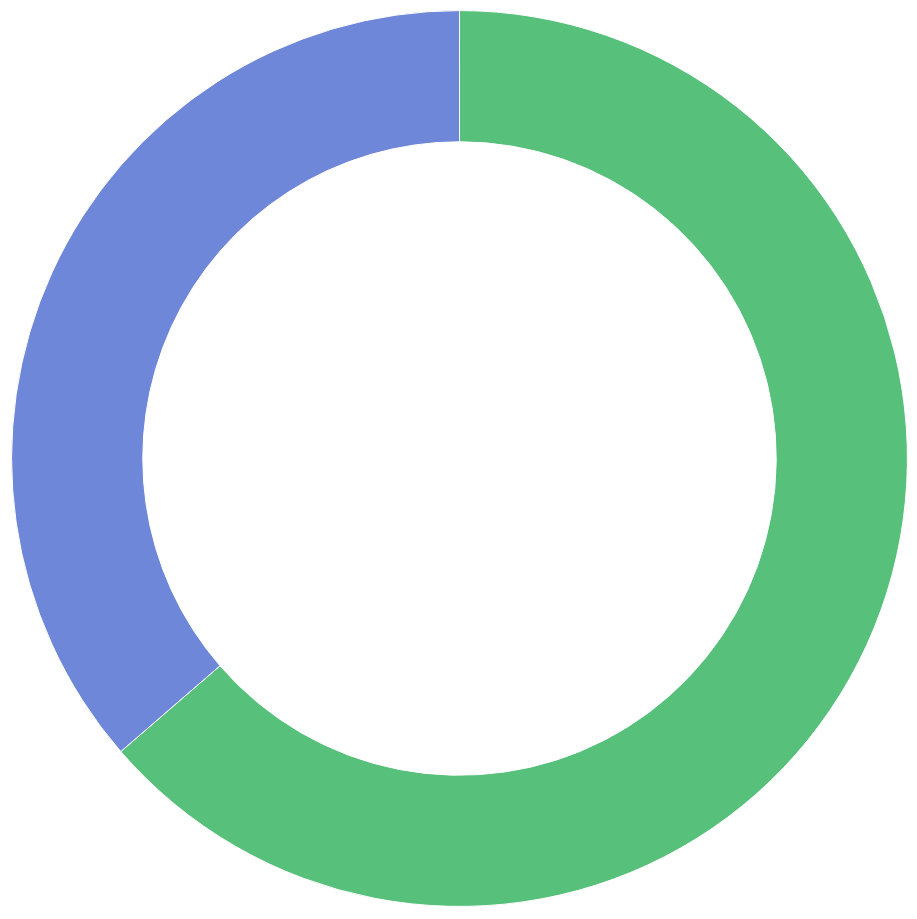
- A list of all records containing subject information:
_exists_:subject - And here is a visualization comparing the number of entries with subject information (green) to those without (blue)
Using Kibana and adding visualizations
Feel free to play around with the index and Kibana. You can also create other interesting visualizations. Just take a look at the examples as template.
Lessons Learned
We have learned a lot creating the JSON-LD and indexing it. For example, the Kibana index pattern page is a good place to find problems in the creation of the compacted JSON-LD. Specifically, we would check for keys that still contain “http” to find out which properties are missing in the context document. As the index pattern page is itself based on the GET mapping API, this insight led us to use the mapping API to create an automatic check against the lobid-gnd data for not compacted keys.
Another thing we have learned that it is probably better to create a JSON context by hand than creating it from the ontologies used in a dataset. The ontology approach will give you lots of things in the context that aren’t actually used in the data. (Anybody for creating a tool to automatically create a JSON-LD context based on an RDF dataset as input?)
Feedback to LoC
Working with a dataset always reveals some things that are not correct or could be improved. We collected those in a separate issue to be submitted to the Library of Congress. Here is what we found while working on this:
- A canonical JSON-LD context for the dataset is missing.
- The list of contributors from
bf:contributionis not an ordered list, thus missing the contributor order from the actual resource. - Some properties are used in the dataset whose URIs do not resolve:
http://id.loc.gov/ontologies/bflc/consolidates,http://id.loc.gov/ontologies/bflc/relatorMatchKey,http://id.loc.gov/ontologies/bflc/procInfo,http://id.loc.gov/ontologies/bflc/profile - There are redundancies between classes in the MADS and Bibframe vocabularies which both are used:
bf:GenreFormandmads:GenreForm,bf:Temporalandmads:Temporal,bf:Topicandmads:Topic - In the dataset, the wrong URI is used for
mads:isMemberOfMADSScheme(instead o an upper case “O” lower case is used). - Instead of the correct
bf:instrumentalTypethe following is used:bf:instrumentType
Comments? Feedback? Just add an annotation with hypothes.is.